Does schema markup actually impact AI citations?
An honest analysis of the Ahrefs study and the three layers it didn't measure

The Ahrefs schema study landed this week and half of SEO LinkedIn is doing a victory lap. Schema is dead, GEO was hype, everyone with a structured-data SaaS is panicking.
I read the same study and changed exactly zero things in our playbook.
This is the long version of why. If you want the short version, read the LinkedIn post here and skip the deep dive. If you want the framework I use to decide what actually moves AI citations for a given customer, keep reading.
What the Ahrefs study measured
Ahrefs published a difference-in-differences analysis of 1,885 pages that added JSON-LD schema between August 2025 and March 2026. They matched each treated page against 3 control pages with similar baseline citation counts and measured the change in citations across Google AI Overviews, AI Mode, and ChatGPT.
The headline finding: adding schema produced no statistically significant lift on AI Mode (+2.4%) or ChatGPT (+2.2%), and a small negative effect on Google AI Overviews (-4.6%).

Ahrefs DiD chart: treated vs control pages. Source: Ahrefs
Credit where it's due: the methodology is clean for what it measured. Matched controls + DiD is about as rigorous as you get for an observational study. And to their credit, Ahrefs explicitly acknowledged the gap in their own caveats section.
What the study didn't measure
This is the part that got lost in the LinkedIn dunking.
Every page in Ahrefs' treated group had 100+ AI citations before they added schema. Every single one. That means the study only answers one question: does adding schema amplify citations on pages AI is already loving?
Answer: no. Real result.
But there are at least three layers schema operates on that the study could not measure by design:
Pool entry. Does schema help a page get INTO the citation pool in the first place?
Entity disambiguation. Does schema help AI retrievers understand which specific entity your page is about?
Retrieval-time grounding. Does schema feed the indexing pipelines that LLMs use to retrieve candidates?
Ahrefs measured what happens after a page is already inside the pool. The interesting questions all live upstream of that.
Layer 1: How AI search actually retrieves content
Modern AI search isn't one model. It's a pipeline.
User asks a question to ChatGPT, Perplexity, Gemini, or Google AI Overviews.
A retriever pulls candidate pages from an index (usually 10–100 of them).
Those candidates get passed to the LLM as context.
The LLM generates the answer, sometimes citing the candidates.
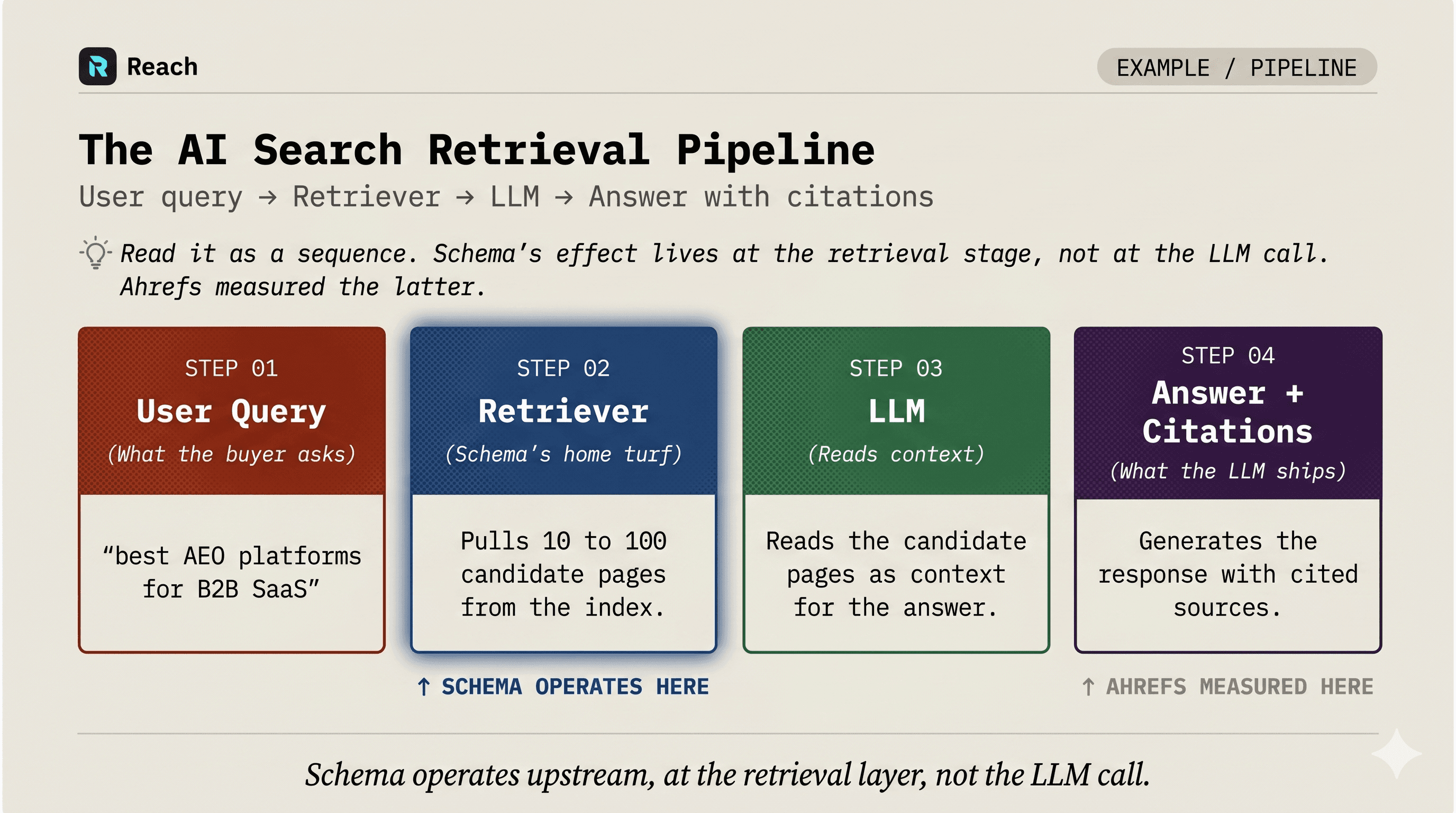
The four stages of AI search retrieval. Schema's effect lives at step 2 (retrieval), but Ahrefs measured outcomes at step 4 (citation).
Step 2 is where pages get INTO the pool. Step 4 is where the LLM decides who to actually cite — the part Ahrefs measured.
SearchVIU's 2026 study tested whether five major LLMs (ChatGPT, Claude, Perplexity, Gemini, Google AI Mode) parse JSON-LD at fetch time when retrieving a page live. The result: none of them do. Every system extracted visible HTML content only. JSON-LD, hidden Microdata, and hidden RDFa were all ignored at the LLM-fetch layer.
So if schema doesn't affect what the LLM sees at fetch time, and Ahrefs proved it doesn't affect citation rates among pages already in the pool, where exactly does schema work?
Upstream. At the retriever and the entity layer.
Bing publicly admitted in May 2026 that they run a separate "grounding indexing" pipeline that consumes structured data BEFORE the LLM ever sees a page. The pipeline produces an enriched candidate set that gets passed to Copilot's LLM. Schema flows into that pipeline. The grounding signals affect what enters the candidate set, not what the LLM does with already-selected candidates.
That's where the schema effect actually lives. Ahrefs measured the wrong end of the pipeline.
Free Audit
See which of your pages are showing up in AI answers today
The Reach AEO audit maps every page on your site against the buyer prompts you're trying to win, and shows you where you are and aren't being cited in ChatGPT, Perplexity, AI Mode, and AI Overviews.
Layer 2: Entity graphs and the "which Reach?" problem
Every major search engine maintains an entity graph.
Google has the Knowledge Graph (every entity has a unique Machine ID, like
/m/0c8tk_). It's been around since 2012 and powers entity panels, knowledge cards, and increasingly the entity-resolution layer behind AI Mode and AI Overviews.Bing has Satori, their KG, named after the Japanese term for sudden understanding. Powers entity cards, Bing Search APIs, and Copilot's grounding pipeline.
These graphs are built from Wikipedia, Wikidata, schema.org markup on the web, and structured feeds from licensed data partners. AI retrievers inherit them. ChatGPT's web search runs on Bing's index, which means ChatGPT indirectly inherits Satori. Google AI Mode and AI Overviews query the full Knowledge Graph natively.
Why this matters in practice: take the brand name "Reach." There's Reach plc (the UK media company), Reach dental floss (a Johnson & Johnson brand), Reach Robotics, Reach Industries, and a dozen other startups named Reach. When a buyer asks ChatGPT about AEO platforms, the retriever has to decide which Reach is the right entity to pull pages from.
If our pages don't explicitly tell Bing and Google's entity graphs "we are THIS specific Reach, here are our canonical external references," the retriever has to guess. Sometimes it guesses right. Often it doesn't. The Reach plc article on the BBC outranks our actual product page because Reach plc has 30 years of entity-graph density and we don't.
The fix is schema with sameAs properties pointing to external trusted references for each entity on the page. That's the literal handshake to the knowledge graphs.
Here's what proper Organization schema with entity disambiguation looks like:
This isn't just one type of schema. Entity disambiguation works across multiple types depending on what's on the page:
Organizationfor the company itselfSoftwareApplicationfor the productPersonfor each founder, exec, and author (with their ownsameAsto LinkedIn, X, personal sites)Articlewithmentionsarrays for every notable entity discussed in the postProductfor individual product offeringsEventfor webinars, conferences, panels
Each one tells the entity graph about a different node. Combined, they build a coherent entity record across your whole site.
Layer 3: What to put on each page type
Here's the page-by-page reasoning I apply for B2B SaaS sites. The principle: every page is about one or more entities, and schema is how you tell machines which entities are present and how they relate.
Homepage
The entities are your Organization, your SoftwareApplication, and the WebSite itself. The homepage is the canonical "About this Entity" page from a KG perspective. Everything downstream inherits from what you declare here.
About / Company page
Entities: Organization plus a Person block for each founder and exec. The worksFor property on each Person links them to the Organization. That's how knowledge graphs build founder-to-company relationships.
Product / Features pages
Entities: SoftwareApplication, Offer (or AggregateOffer on pricing pages), AggregateRating if you have legitimate reviews, and FAQPage for any Q&A blocks (still ingested by LLMs even though Google killed the rich snippet).
Blog post (the page you're reading)
Entities: Article, Person (author), Organization (publisher), BreadcrumbList, FAQPage at the bottom, plus a mentions array linking to every notable entity discussed in the post. The mentions array is one of the most underused schema properties and one of the most useful for AEO.
Customer case study
Entities: Article with an author (Reach) and a mentions entry pointing to the customer's canonical Organization. Optionally a Review with the customer as author and Reach as itemReviewed. This is how you build entity-to-entity relationships in your favor.
Careers / Job page
JobPosting plus Organization (hiringOrganization). Marks your team-growth signals in the entity graph.
Webinar / Event page
Event with Person speakers and Organization organizer. Connects your brand to the speakers' entity graphs.
Layer 4: sameAs and the cross-page consistency rules
sameAs is the literal handshake to knowledge graphs. It's where you say "the entity on this page is THE SAME as the entity at these external authoritative URLs."
What to include in your Organization sameAs:
LinkedIn company page
Crunchbase profile
AngelList / Wellfound profile
X (Twitter) profile
ProductHunt (if listed)
Wikidata URL (if a Q-number exists)
GitHub (if applicable)
The five rules most sites get wrong:
The
sameAsarray must be identical on every page where your Organization appears. Different arrays across pages = drift = downweighted in the KG.Organization properties must match exactly across pages. Same legal name, same founding date, same logo URL.
Use
@idto link entities across pages. Assign a stable URI likehttps://usereach.ai/#organizationand reference it everywhere. That's how you tell crawlers the Reach mentioned here is the SAME entity as the Reach in every other page.Schema must match the visible content. If your
mentionsarray names ColdIQ but the article doesn't actually mention ColdIQ, that's spam in the eyes of crawlers.dateModifiedmust update only when content changes. A lot of CMSes auto-set it on every page load. That's fake freshness. AI retrievers downweight fake freshness signals fast.
The part nobody is talking about
So far we've covered three layers Ahrefs didn't measure: pool entry, entity disambiguation, and retrieval-time grounding. Schema works at all three.
But there's a fourth question that no observational study can answer: once you ARE in the retrieval pool, what makes the LLM actually cite YOU instead of the other 50 candidates?
That's not a schema problem. It's not even one problem.
We've now run citation pattern analysis across every B2B customer Reach has onboarded. The patterns are different every single time.
For one SaaS, the unlock was anchor text on third-party review sites that fed Bing's entity graph.
For another, a single mid-funnel article anchored a whole cluster of prompts because the LLM kept pulling it as the canonical explainer.
For a third, the page getting cited wasn't even theirs. It was a Reddit thread the model treated as the authority for that topic.
For a fourth, the answer was a podcast transcript indexed by Perplexity.
There is no universal playbook for what makes a specific model cite a specific brand for a specific prompt. The work is per-customer, per-cluster, per-prompt.
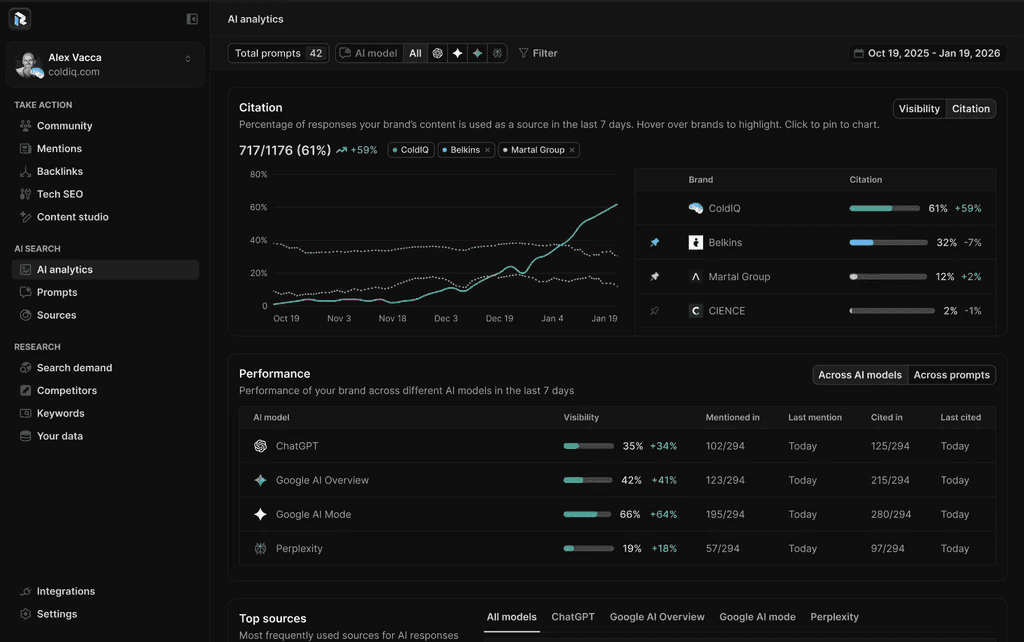
ColdIQ's AI citation growth on monitored buyer prompts, starting from 0% visibility. See the full case study.
You can see the depth of this in the ColdIQ case study. $506K in influenced contract value in 4 months. AI visibility from 0% to cited in 52% of 120 tracked prompts. No single schema or content tactic moved that needle. It was a series of per-cluster bets that we ran, measured, and iterated.
Combined SEO + AI search became ColdIQ's #1 traffic source within 4 months (16.5% → 33.3% of total traffic).
What you should actually do this week
If you read the Ahrefs study and were tempted to deprioritize schema, here's what I'd suggest instead.
Audit your Organization and Person schema. Make sure your homepage and About page both declare full Organization schema with consistent sameAs arrays pointing to your canonical external references. Same for Person schema on every author byline.
Add mentions arrays to your articles. Every blog post, every case study, every guide should declare which entities it's about. This is the most underused schema move in AEO.
Don't expect schema to fix amplification. If your pages are already cited 100+ times by AI, adding schema won't 2x your citations. Ahrefs proved that. Schema is a foundation, not a multiplier.
Run your own DiD test if you're not sure. Pick 10 pages where you're adding schema, 10 control pages where you're not, measure citations across the same 60 days. Ahrefs even published a guide for how to do this yourself.
Treat citation pattern as per-customer work. The biggest lift from AEO isn't schema, it's understanding the specific retrieval and citation patterns that drive your specific buyer's prompts.
Free tool
Monitor your AI citations across ChatGPT, Perplexity, AI Mode, and AI Overviews
Our free LLM dashboard tracks which of your pages are getting cited in AI answers, which prompts you're showing up for, and where you're losing to competitors. No credit card, no upgrade gate.
Frequently asked questions
01
Does schema markup affect AI citations?
Indirectly, yes. Schema doesn't change what an LLM does with a page after retrieval, as Ahrefs' 2026 study confirmed for pages already cited 100+ times. But schema feeds the retrieval-time grounding pipelines (Bing publicly admitted this in May 2026) and the entity graphs (Google's Knowledge Graph and Bing's Satori) that AI retrievers query when assembling candidate pools.
02
What's the difference between schema for SEO and schema for AI search?
For traditional SEO, schema mostly drives rich-result eligibility (FAQ rich snippets, product star ratings, breadcrumb display). For AI search, schema operates one layer further upstream: it feeds entity disambiguation in knowledge graphs and the grounding pipelines that determine which pages enter an LLM's candidate set for a given query.
03
Do LLMs read JSON-LD when they fetch a page?
No. As of 2026, none of the major LLMs (ChatGPT, Claude, Perplexity, Gemini, Google AI Mode) parse JSON-LD at fetch time. They extract visible HTML only. JSON-LD impacts AI citations through the retrieval and entity-graph pipelines that run before the LLM sees the page.
04
Which schema types matter most for AEO?
Organization and SoftwareApplication for entity foundation, Person for author authority, Article with mentions arrays for relational context, FAQPage for matching buyer prompts, and BreadcrumbList for site-structure signals.
05
What's the most underused schema property for AEO?
The mentions array on Article schema. It explicitly declares which entities are present in the post, which feeds knowledge graphs the relationship signals they use to surface your content for entity-shaped queries.
06
Is FAQ schema still worth adding now that Google killed FAQ rich results?
Yes. Google officially deprecated FAQ rich snippets on May 7 2026, but the underlying mechanism still works. Google explicitly said they'll keep using FAQ structured data to understand pages, and LLMs still ingest the Q&A pairs from JSON-LD.